
ディープラーニングや機械学習を利用した開発・運用をする際、AWS等のクラウドサービスを利用したいものの、コストが悩みのタネという方が多いのではないでしょうか。当社モルゲンロットでは、このようなお悩みを解決するため、コストパフォーマンスの良いAMD社製GPUを利用したサービス「M:CPP」を提供しております。
このとき、次のような疑問が浮かんでくることでしょう。
- AMD製GPUで正しく・速くディープラーニングの学習ができるのか?
- 実際にどのくらいコストが安くなるのか?
1つ目の疑問については、過去のブログ記事「AMDのGPUでディープラーニングのフレームワークの動作を検証」で紹介したとおり、TensorFlowやPyTorch、Kerasで画像の物体検出などの学習を実行できることを確認しました。この記事では、さらに学習の実行時間や学習結果のモデルの精度についても検証します。
2つ目の疑問についてはAWS(Amazon Web Services)を比較対象とした検証結果を紹介します。M:CPPとAWSでの学習時間と、時間あたりの利用料金からコストパフォーマンス(料金あたりの学習量)を比較しました。結果としては、AWSの最安リージョンに対してM:CPPを利用すると最大2倍のコストパフォーマンスが得られることが示されました。
評価条件
比較対象のサービス
比較対象のサービスとしては、NVIDIA社のGPUを使えるサービスの代表としてAWSを選定し、インスタンスはGPU 1つで機械学習実行のための基本的なプランである「p2.xlarge」としました。M:CPP側は、これに極力近い「プラン]として「LOW Ve-32-r7」を比較対象としました。
インスタンスのスペック比較です。
| 比較項目 | AWS | M:CPP |
|---|---|---|
| プラン | p2.xlarge | LOW Ve-32-r7 |
| RAM [GM] | 61 | 32 |
| ストレージ [GB] | 230 | 230 |
| CPU | Intel Xeon E5-2686 v4 | AMD Ryzen7 2700 |
| ベースクロック | 2.7 GHz | 3.2GHz |
| スレッド数 | 4(仮想割当) | 16 |
| GPU | NVIDIA GK210 x1(K80のGPU2基のうち1つ) | Radeon RX Vega56 x1 |
| 単精度演算性能 [TFLOPs] | 9.74(参考値:K80のBoost時) | 10.5(ピーク時) |
| GPUメモリ [GB] | 12 | 8 |
CPU、GPUともに、M:CPPの方が、総合的に処理性能が高くなっています。
学習条件
学習するタスクとしては、次の3つを実施しました。
備考:
これらの公式サンプルコードをそのまま動かしましたが、TensorFlowのClassification についてはそのままだと比較可能なほど学習が収束していないので、Epoch数を30から150にしました。また、PyTorchではDockerを利用し、TensorFlowではDockerはなしでAnacondaを利用しています。
実験結果
学習結果の精度
まず、M:CPP上のAMD製GPUで学習したモデルの精度が、AWS上のNVIDIA製GPU利用時と同等かを見てみましょう。
各学習結果の精度(Validation Accuracy)の値と、その値の各サービス間の比率(M:CPP/AWS)です。
| フレームワーク | 学習タスク | AWS | M:CPP | 比率(M/A) |
|---|---|---|---|---|
| Pytorch | MINIST | 0.99 | 0.99 | 1.00 |
| TensorFlow | classification(犬猫) | 0.76 | 0.76 | 1.00 |
| segmentation(犬猫) | 0.89 | 0.89 | 1.00 |
すべての学習で、どちらのサービスでもほぼ同じ精度となっていることが確認できました。AMD製GPUでも安心だといえます。
学習の実行時間
各学習の実行時間、その値の各サービス間の比率(M:CPP / AWS)です。
| フレームワーク | 学習タスク | AWS [秒] | M:CPP [秒] | 比率(M/A) |
|---|---|---|---|---|
| Pytorch | MINIST | 216 | 135 | 0.62 |
| TensorFlow | classification(犬猫) | 2611 | 1658 | 0.64 |
| segmentation(犬猫) | 325 | 211 | 0.65 |
PyTorch、TensorFlowともに、各学習タスクでM:CPPではAWSに対して64%前後の時間で学習が完了しています。言い換えると、M:CPPではAWSに対して約1.57倍の学習速度となっています。
コスト比較
比較条件
比較対象のAWSインスタンスはp2.xlargeですが、AWSではリージョンやプランによって料金が変わるため、いくつかの条件での料金と比較します。
料金プラン
M:CPPは月額料金で1ヶ月からご契約頂けるようになっています。これと比較するため、AWSの料金プランとしては、「オンデマンド」で1ヶ月使い続けた場合と、「All Reserved」「EC2 InstanceSavings Plans」の一年契約前払いあり・なしでの1ヶ月あたりの料金としました。
AWSのリージョン
リージョンの選択はサービス利用のユースケースによるので、次の2つを比較対象としました:
- 「US East (N. Virginia)」:「モデル開発」であれば遠くても安い物が良いという想定で、記事執筆時点で最安のリージョンを選びました。
- 「Asia Pacific (Tokyo)」:「機械学習モデルを利用したサービス運用」であれば日本のサーバーが良いという想定で、東京リージョンを選びました。
他、AWSでの条件詳細:
- Snapshot なし
- Data Transfer なし
- ストレージはGeneral Purpose SSD(gp2) の230GB (M:CPPでのプランに合わせる)
- AWSの料金は[公式シミュレーション]による値(USD)に対して、USD/JPY=110として算出したもの
利用料金の比較
各サービス・プランでの1ヶ月あたりの利用料金の比較です:
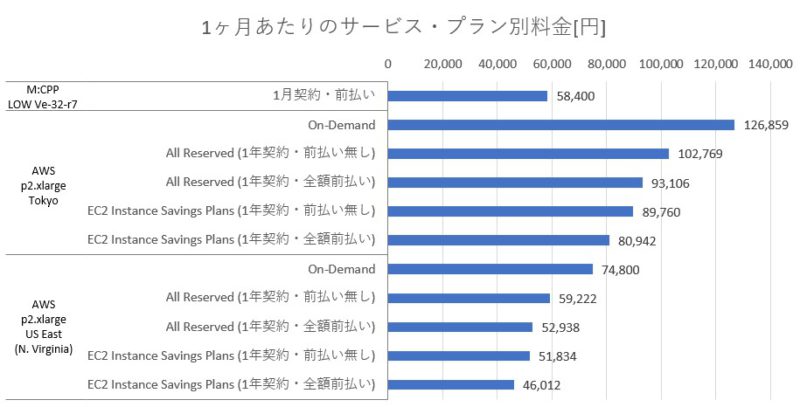
1ヶ月あたりの料金自体はAWSでの最安リージョン(N. Virginia)では支払いプランによってはM:CPPの方が高くなるケースもありますね。
コストパフォーマンスの検証
それでは、コストパフォーマンスを見るとどうでしょうか?
M:CPP(LOW Ve-32-r7)の月額料金は58,400円ですが、この料金を0.64倍(AWSに対する学習時間の比率)し、「AWS(p2.xlarge)が1ヶ月間で実施できる学習を、M:CPP(LOW Ve-32-r7)ならいくらでできるか」を算出すると、37,376円となります。それでは、この値と、AWS(p2.xlarge)の値段を改めて比較してみましょう:

M:CPPが最もコストパフォーマンス(料金あたりの学習量)が良くなっています。
たとえば、N. Virginiaのオンデマンドプランに対しては2.001倍のコストパフォーマンスとなっています。
なお、ここで挙げているAWSのオンデマンド以外のプランは最低1年の契約が必須なために安くなっているものですが、M:CPPは1ヶ月から契約可能なプランでこの価格となっています。
まとめ
M:CPP(LOW Ve-32-r7)では、AWS(p2.xlarge)と比べ、代表的なディープラーニングの学習が64%前後の時間で実行できること(=約1.57倍の学習速度)、またAWSに対して最大約2倍のコストパフォーマンスが得られることがわかりました。
さらに、M:CPPでは長期契約等によるディスカウントやご要望に応じてインスタンスのスペックの調整も実施しておりますので、お気軽にご相談ください。また、ビジネスユーザーの方を対象とした1ヶ月間の無料体験も実施しています。