TL;DR
- Amazon ECS Anywhereを用いると、AWSからAWSの外部にあるサーバに対しコンテナをデプロイすることができる
- ECS Anywhereを用いてAWSから外部のGPUサーバにディープラーニングの学習をするコンテナをデプロイし、問題なく実行できることを確認した
- AMD社製のGPUサーバを外部インスタンスとして使用する際は、タスク定義の際にdevicesとshm-sizeを指定する必要があることに注意
はじめに
現在、多くのビジネスシーンにおいて機械学習が活用されています。近年は機械学習の中でも特にディープラーニングを用いたシステムが増えてきているのではないでしょうか?画像・音声・自然言語領域などで、革新的なサービスがいくつも誕生しています。
このように現代ビジネスの鍵となる可能性を持つディープラーニングですが、「サーバのコストがかかる」という課題があります。ディープラーニングの学習に使用するGPUサーバは時間あたりのコストがCPUのみのサーバに比べて高く、さらに学習にかかる時間が長いためです。
そのため、以下のような悩みを抱えている方が多いのではないでしょうか?
- 運用しているサービスをすべてパブリッククラウド上で動かしているが、サーバにかかるコストが高い。
- 機械学習以外の部分をパブリッククラウド上で動かしており、機械学習はオンプレミスで行っている。しかし、両方の環境を保守する管理コストが高い。
- ほとんどのワークロードをオンプレミスで行っているが、クラウドに移行したい。しかし、サーバにかかるコストを考えると移行に踏み切れない。
そんな中、2021年5月にAWSからAmazon ECS Anywhereという機能がリリースされました。このECS Anywhereを使用すると、AWS上に作成されているECSクラスタにAWS以外の環境にあるサーバを追加することができます。
これにより、コンテナオーケストレータをAWS上においたままAWS外のサーバにコンテナをデプロイすることができるようになります。このECS Anywhereを活用して、先述のサーバにかかるコスト/管理にかかるコストを削減することができそうですよね。
そこで、本記事ではECS Anywhereを用いてAWSと外部のGPUクラスタを連携させる方法をご紹介します。なお、今回はAMD製のGPUが搭載されたサーバを外部クラスタとして使用します。
AMDのGPUでディープラーニングの計算を実行することそのものにご興味があるかたは、以下の記事をご覧ください。
Amazon ECS Anywhereについて
Amazon ECS Anywhereは、AWSのElastic Container Service(ECS)の機能の一つです。この機能を活用すると、クラスタをAWS上においたままAWS以外の環境にあるサーバに対してコンテナをデプロイすることができるようになります。
AWS以外の環境にあるサーバを有効活用するという意味でサーバ代のコスト削減につながりますし、コンテナオーケストレーションの管理を一元化できるという観点では管理コストを削減することにもつながると考えています。
以下の記事に、ECS Anywhereを使用するモチベーションについて素晴らしい説明があるので、詳しくはそちらをお読み頂けると幸いです。
ディープラーニングの学習を行う検証
本項では、ディープラーニングの学習を外部GPUサーバで行う検証を試みます。
解説の方針
すでにECS Anywhereについての素晴らしい記事がインターネット上にあるので、重複する部分はそちらへのリンクで済ませ、本記事固有の操作のみ解説を行います。
- AWS公式ドキュメント: 外部インスタンス(外部リンク)
- DevelopersIO: ECS Anywhere を Azure と Google Cloud (GCP) を使って動かしてみた(外部リンク)
また、これ移行の手順では、AMD製のGPUが搭載されたサーバにデプロイするため、「ROCm」などの単語が解説なしで使用されます。前提知識を得るためには以下の記事をお読み下さい。
検証する内容
今回は、以下のようなジョブを実行してみます。
- PyTorchの公式exampleをgit clone
- MNISTの学習を実行
- 学習されたモデルをS3にアップロード
前提
以下の状態を前提として解説します。
- AWSのアカウントが既に存在する。
- AMDのGPUが搭載されたサーバが既に存在し、ssh接続可能である。
- 上記サーバにROCmが既にインストール済みである。
手順
1. Docker Imageを作成し、Docker Registryにpushする
まずは、Docker Imageを作成します。以下のようにtrain.shを作成しておきます。「検証する内容」の通りなので説明不要かと思います。
git clone https://github.com/pytorch/examples.git
cd examples/mnist
python main.py –save-model
aws s3 cp mnist_cnn.pt s3://mcpp-tmp/
Dockerfileは以下のように作成します。
ベースのイメージに公式が配布しているROCm+PyTorchのイメージを使用し、先程作成したtrain.shを配置します。
注意点は以下2点です。
- ベースイメージのROCmのバージョンを、デプロイ先のGPUサーバに入っているROCmのバージョンと揃える必要がある
- aws cliのインストールが必要となる
FROM rocm/pytorch:rocm4.2_ubuntu18.04_py3.6_pytorch_1.8.1
RUN sudo apt-get -y install unzip
RUN curl “https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip” -o “awscliv2.zip” && unzip awscliv2.zip && sudo ./aws/install
WORKDIR /working
COPY train.sh /working
RUN chmod 755 /working/train.sh
CMD /working/train.sh
完成したら、このイメージを使用できるようにどこかのDocker Registryにpushしておきます。
今回の検証では、AWSのECRを使用しました。
2. ECSクラスタを作成し、Externalインスタンスを登録するためのコマンドラインを生成する
続いて、ECSクラスタを作成します。ここで、タスクを実行するためのインフラを定義します。
また、インフラに外部サーバを追加するためのコマンドをAWSに生成してもらいます。このコマンドを3.で実行する流れです。
詳しい手順は、ECS Anywhere を Azure と Google Cloud (GCP) を使って動かしてみた(外部リンク)内の
- ECSクラスタを作成する
- Externalインスタンスの登録準備 (アクティベーションコードの払い出し)
を参考にしてみてください。
3. GPUサーバをExternal Instanceとして登録する
外部のGPUサーバにssh接続して2. で生成されたコマンドを実行します。AWSと外部GPUサーバとの接続はこのコマンド実行のみで完了します。
詳しい手順は、ECS Anywhere を Azure と Google Cloud (GCP) を使って動かしてみた(外部リンク)内の
- Externalインスタンスの登録
を参考にしてみてください。
4. ECSのタスク定義を作成する
次に、タスク定義を作成します。
まず、タスク定義の前に1.で作成したコンテナをローカルで実行するコマンドについて確認しておきましょう。作成したコンテナは最もシンプルにした場合以下のコマンドで実行されます。
sudo docker run –device=/dev/kfd –device=/dev/dri –shm-size=2gb pytorch_train_example:latest
このdeviceオプションおよびshm-sizeオプションに相当するものをタスク定義に付与することが大切であることにご注意下さい。
deviceオプションは、GPUデバイスをコンテナに認識させるために必要なコマンドです。
shm-sizeは、shared memoryのサイズです。機械学習をDockerコンテナ上で行うとshared memoryが不足して突然処理がabortされてしまうことが良くあるため、大きめにサイズを指定しています。
それでは手順の紹介に入ります。この項目は他の記事に含まれない内容も記載するため、詳しく解説していきます。
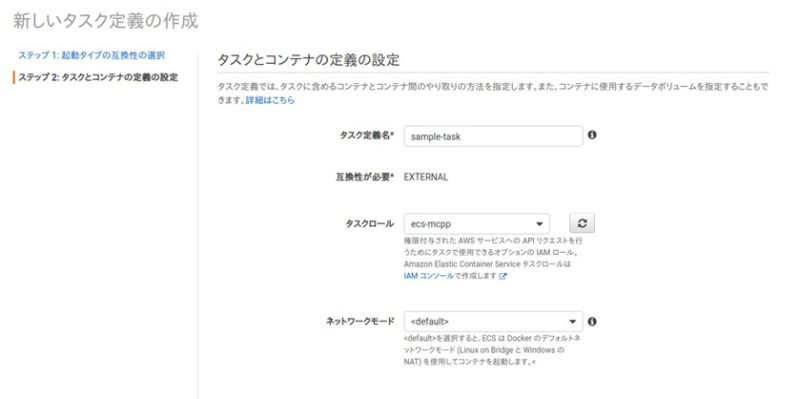
まず、「新しいタスク定義の作成」にて、起動タイプをEXTERNALにして次のステップに移動します。
.jpg)
次に、タスクとコンテナの定義を設定していきます。
タスクロールとは、コンテナ内部からAWSのリソースを使用する際のロールです。今回は学習結果をS3にアップロードするため、S3へのアクセス権限があるロールを作成して指定しています。
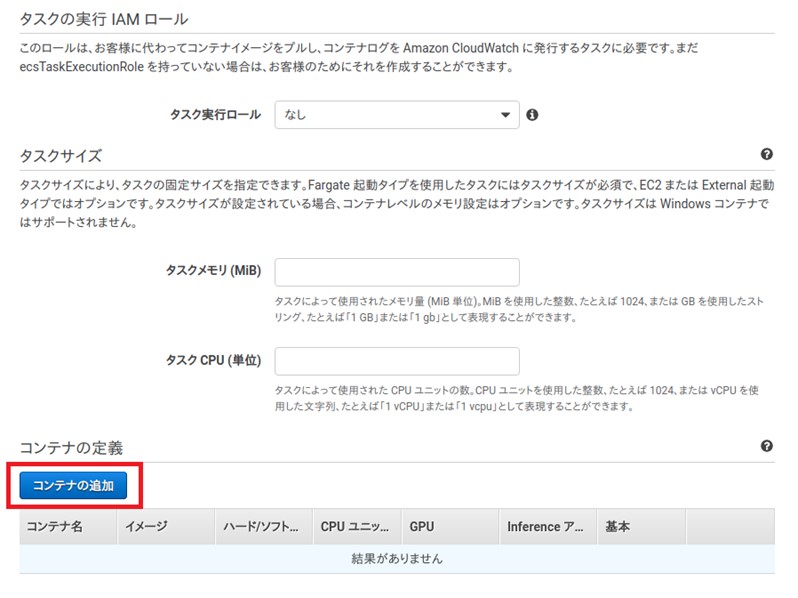
続いて、以下の「コンテナの追加」を押下してコンテナを登録します。
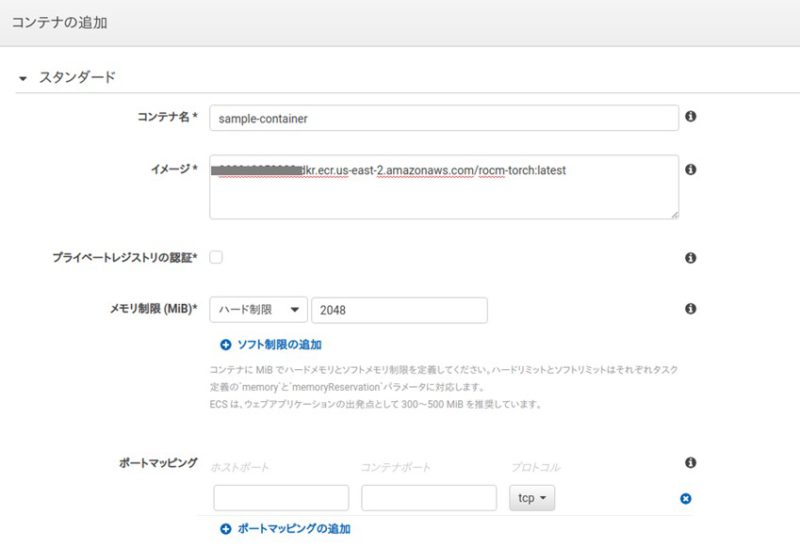
コンテナ名、イメージ、メモリ制限を指定します。イメージは1.で作成したものを指定します。
今回はただ学習を行うだけなのでポートマッピングは指定しませんが、たとえばTensorBoardを使用したい方などは適宜指定してみてください。
最後に、先述のdeviceオプション、およびshm-sizeオプションに値する部分を指定します。
以下の「JSONによる設定」を押下します。
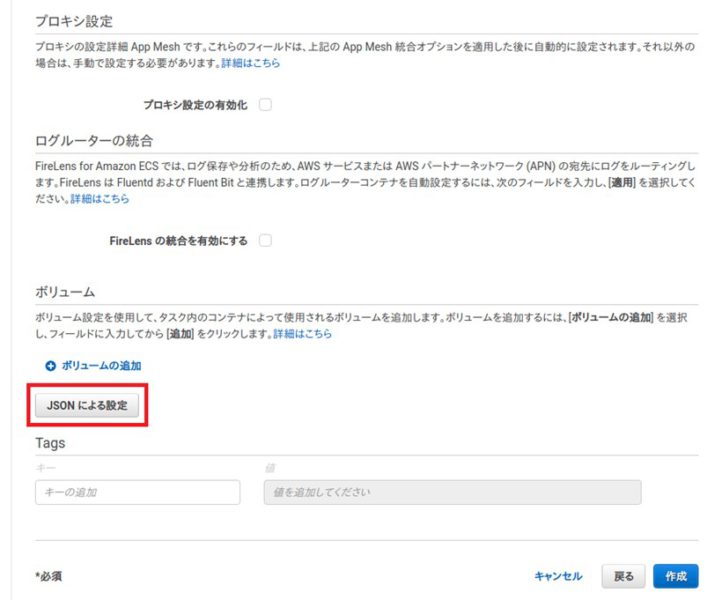
JSONの”containerDefinitions”というキーに以下のようなDictionaryを追記します。sharedMemorySizeの単位はMBであることに注意してください。
“linuxParameters”: {
“sharedMemorySize”: 2048,
“devices”: [
{“hostPath”: “/dev/kfd”},
{“hostPath”: “/dev/dri”}
]
}

このJSON定義を保存した後、最後に「作成」を押下するとタスク定義の作成が完了します。
5. ECSのタスクを実行する
完成したECSのタスク定義を実行してみます。Web GUIから実行する方法と、コマンド実行する方法の2つをご紹介します。
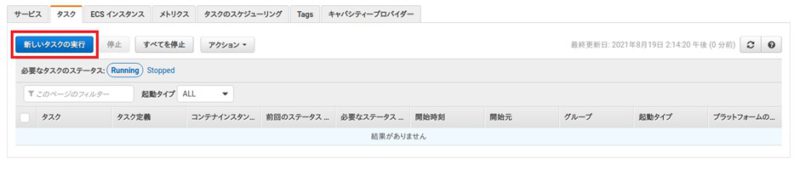
Web GUIから実行する
クラスタの「タスク」タブより、「新しいタスクの実行」を選択します。
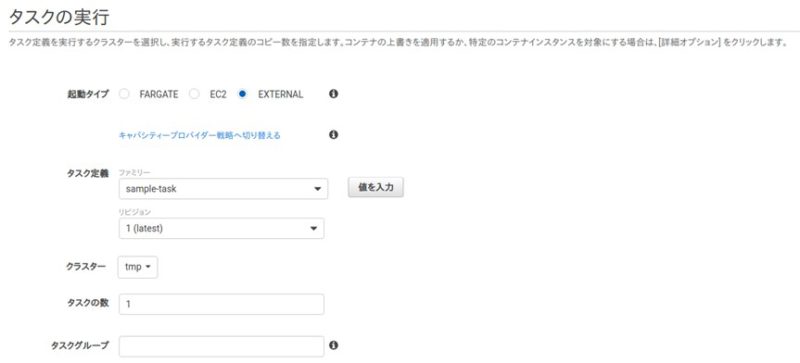
起動タイプをEXTERNALにして、先程作成したタスク定義を指定して実行します。
AWS コマンドから実行する
以下のようにaws cliからも実行可能です。
aws ecs run-task –launch-type EXTERNAL –task-definition <タスク定義>:<リビジョン> –cluster <ECSクラスタのarn> –region <region>
6.動作確認
タスクを実行したら、GPUサーバにssh接続して実行できているかを確認してみます。
まず、docker psコマンドを叩くと、AWSから起動の命令を出したコンテナが外部のGPUサーバで動作していることを確認できます。
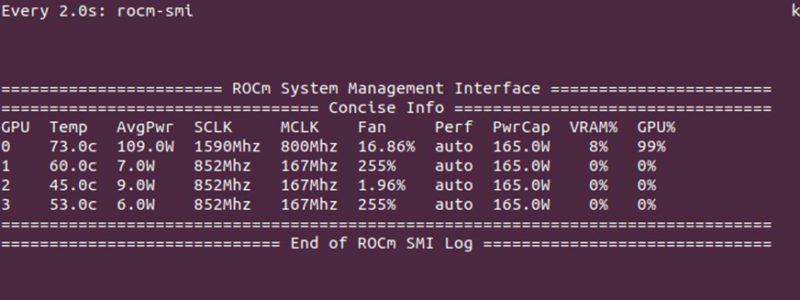
次にrocm-smiコマンドを使用してGPUをきちんと扱えているかを確認してみます。確かにGPUを使用してくれていることが確認できました!
また、学習が終了した後にAWS S3の該当バケットを確認すると、学習済みモデルがアップロードされていることも確認できました。
まとめ・所感
AWS ECS Anywhereを用いて、AWSからAWS外部のGPUサーバに対しコンテナがデプロイできることを確認できました。また、コンテナではAMD製のGPUを用いてディープラーニングの学習を実行できることを確認しました。
今回は単に決まったタスクを実行するのみでしたが、たとえばハイパーパラメータやデータソースを指定しての学習など、より実用的な内容も十分に対応可能であるように感じました。機械学習まわりでクラウドとオンプレの管理にお悩みの方は、ECS Anywhereを実際の業務に活用してみてはいかがでしょうか?
また、当社モルゲンロットが提供する「M:CPP」ではAMD社のGPUが搭載されたサーバを機械学習用にクラウド提供しています。

安価な価格と、カスタマイズ性に優れていることが特徴です。ECS Anywhereを用いたマルチクラウド環境を構築することでトータルコストを抑えることが可能になるケースもあると考えております。よりリーズナブルでハイエンドな環境をお求めの場合には、お気軽にご相談ください。