
ディープラーニングという技術が注目され始めてから数年が経ちました、ディープラーニングが注目され始めたきっかけとなったのが畳み込みニューラルネットワーク(CNN)という技術です。
今回はディープラーニングの技術の中でも、画像認識でよく活用される(CNN)畳み込みニューラルネットワークについて紹介していきます。
人工知能が注目され始めるきっかけとなった技術なのでAI活用を考えている方は知っておいた方が良いです。
CNNでできることやCNNの仕組みについて図を用いて説明していくので、この機会に理解していきましょう。
CNNとは
CNNとは畳み込みニューラルネットワーク(CNN)は、画像からパターンや物体を認識するために最もよく利用されるニューラルネットワークの一つです。
畳み込み層においてフィルタ処理を行うこと(後述します)が大きな特徴として挙げられます。
ここからは、CNNの仕組みについて解説してきます。CNNがなぜ画像認識で高い精度を上げられたかというと、模様や、犬の顔などのより複雑な特徴を学習できるようになったからです。
具体的には、CNN以前は画像を1次元のベクトルとして学習させていたものが、2次元の行列で学習できるようになりました。
これだけだとやや概念的でわかりにくいと思うので、図を使って紹介していきましょう。
CNNが出てくる前の全結合型のニューラルネットワークなどを使った画像認識では、1次元の数字の羅列として学習します。
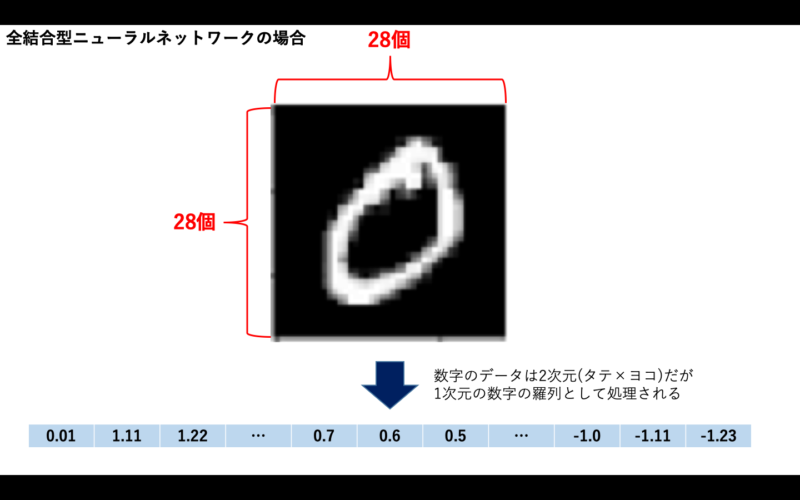
図1:全結合型ニューラルネットワークは2次元の行列を1次元のベクトルに変換する
しかし、2次元の画像のデータでは、あるピクセルとその周りにあるピクセルの関係は、画像の特徴を知る上でとても重要な情報です。1次元のデータとして学習させた場合は、このようなあるピクセルとその周辺のピクセルのような情報は抜け落ちてしまうのです。
そのため、CNNが出てくる前の画像認識は画像の特徴をうまく学習することができずに、精度向上が頭打ちになってしまっていました。画像データをそのまま2次元データとして捉えることができるCNNは、革新的なネットワークだったと言えます。
例えば、MNISTの場合は、白黒の画像を集めたデータセットで背景を黒、数字を白として表現しています。そのため、どこかのピクセルが白であれば、そのピクセルに隣接するピクセルは白である可能性が高くなります(白いピクセルが1個だけ点在しているというケースは数字の場合はないと言って良いでしょう)。
ただし、数字と背景の境界辺りでは、周りに黒いピクセルもあるでしょうし、実際にはそのような白いピクセルと黒いピクセルとの関係が数字の「特徴」を表すことになります。このように、画像には2次元のデータとして学習することで認識できる特徴がいくつもあるのです。

図2:手書き数字「0」の特徴
CNN以前の全結合型ニューラルネットワークを活用した学習の場合、1次元のデータとして学習するので、このような2次元データ特有の特徴を無視することになってしまいます。これらの情報を加味するために活用されているのがCNNです。
CNNでは2次元のデータを小さな区分に分割して、それらと何らかの特徴を表すデータとを比較しながら、元のデータがどんな特徴を含んだものであるかを調べていきます。
何らかの特徴を表すデータのことを「カーネル」と呼ぶことにします。他にはフィルタと言う呼び方をしたりもします。文脈によって違う言葉が使われていたりするので注意しましょう。
話を単純化するために、5×5ピクセルのLの画像データとして考えましょう。
- −1:黒
- 1:白
をそれぞれ表すものとします。
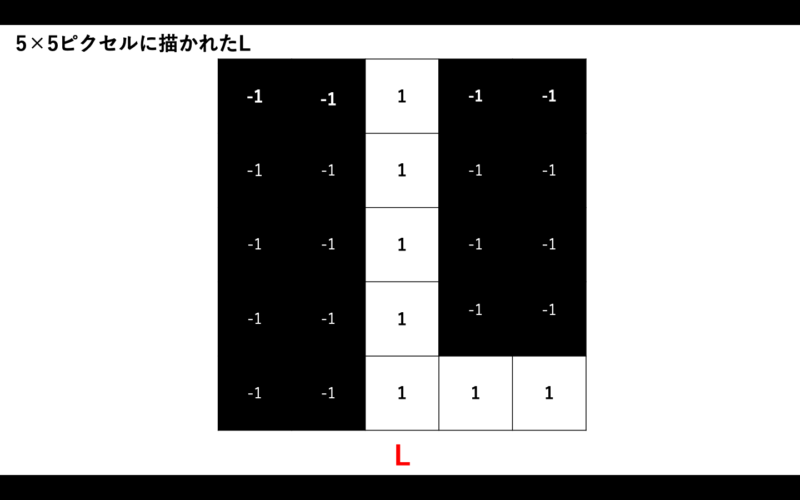
図3:5×5ピクセルに描かれたL
ここで、Lにはどんな特徴があるでしょうか?
- 縦線(|)がある
- 横線(-)がある
- それらが直角に交差する
カーネルとはこのような特徴を表すもので、画像データ(を分割した小さな部分)にどんな特徴が含まれているかを調べるために使われます。
実際には、Lの特徴で記述したようなものを人間が書く必要はありません。CNNを使うと、ある画像がどんな特徴を持っているかニューラルネットワークが学習してくれいます。
その具体的な過程として、プーリングや活性化関数などの処理を経て、全結合を行うネットワークに接続され、その画像が何であるかの推定を行います。
その詳しいプロセスについてはプーリングや全結合層の欄で紹介します。その前に畳み込みニューラルネットワーク(CNN)の畳み込みとは一体どんな処理なのか解説します。
畳み込みとは
畳み込みでは実際にどんな処理が行われるのか、図を使って解説していきます。
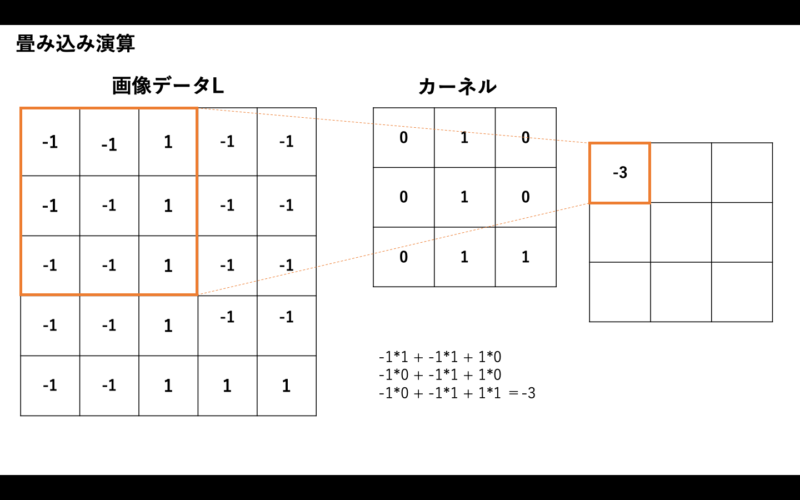
図4:畳み込み演算
カーネルは、3×3などの小さな2次元データだと考えてください。ここでは3×3のサイズの2次元配列とし、これと先ほどのLのデータを例として、どんなことが行われるかを紹介します。
この場合の、カーネルの値は学習により得られたものだとします。まず、画像データにカーネルを適用するときの手順は次のようになります。
- 左上から右下に向かって、カーネルのサイズと同じサイズのデータを取り出す。
- カーネルを使って行列の演算を行っていく。
- その結果をCNNからの出力に左上から並べていく。
このように、元の画像データの区画とカーネルとの行列演算を行った結果を出力としていく処理が「畳み込み」です。この出力を「特徴マップ」と呼ぶこともあります。
また、上の例の場合、畳み込みにより、出力データのサイズが元の画像データよりも小さくなっています。入力画像は5×5だったにも関わらず、出力画像は3×3になっています。
このようなデータサイズの減少を避けたり、画像データの端にあるデータを使った畳み込み処理の回数を増やしたりするなどの目的で画像データの上下左右に「パディング」と呼ばれる要素(値は一般に「0」のことが多い)を付加することもあります。
例えば、先ほどのLを表現した5×5の2次元データの周りに0という数字を加えて(パディング)、7×7の2次元データにしてから、3×3のカーネルで畳み込み演算をしたとすると、出力データは5×5になります。このように、元の画像データの外周にピクセルを加えることで、出力データのサイズが変わらないように処理することが可能です。
プーリングとは
そして、CNNではプーリングという重要な処理があります。「プーリング」とは畳み込みによって得た特徴(特徴マップ)から重要な要素は残しながら、データ量を削減する処理です。
入力(特徴マップ)を小さなサイズの区画(2×2、3×3など。これも「ウィンドウ」や「カーネル」と呼びます)に分けて、その区画内で特徴的な値(最大値、平均値など)を取り出して、それをプーリングの出力とします。
ここでは、上で得た特徴マップに対して、2×2のサイズでプーリングを行ってみましょう。多くの場合は最大値を取り出すので、ここでもそうしてみます。
特徴マップは次のようなものでした。
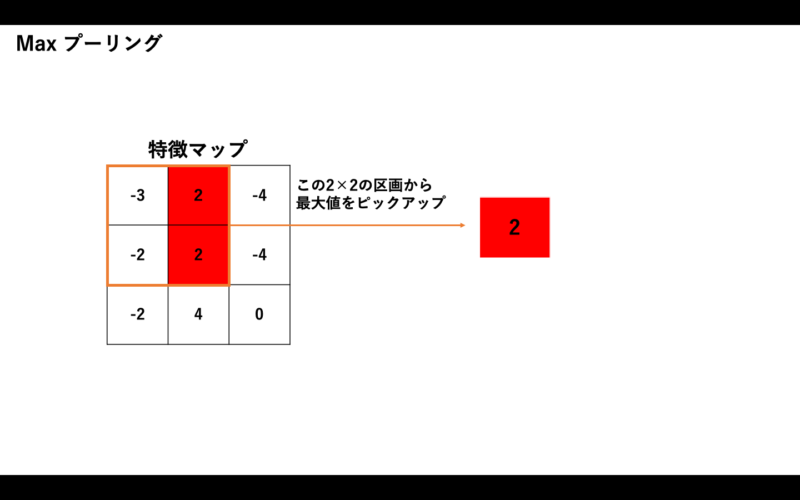
図5:Maxプーリング(最大値を取り出す処理)
元の特徴マップは3×3だったので、そこからプーリング処理を行うことで、2×2の区画から最大値2を抽出することができました。元々の特徴マップのデータ量からデータを削減することに成功しました。
ちなみに、プーリングには畳み込みと同様の特徴があります。それは、入力(この場合は特徴マップ)の中で多少のズレがあっても、もともとの特徴を示すデータをうまく拾い上げられる点です。
画像データはピクセル単位での処理をするので、元のデータや重み、バイアスなどによって、特徴マップのどこに特徴といえる値が出てくるかはそのときどきで変わるかもしれません。
そんなときでも、プーリングを行うことで必要なデータをうまく取り出せるのがプーリングのメリットと言えます。
全結合層とは
全結合層では畳み込みとプーリングを行った後に特徴部分が取り出された画像データを一つのノードに結合し、活性化関数(後述)によって変換された値(特徴変数)を出力するものです。CNNでは、入力画像とそれに対応する正解データが学習データとして与えられます。
そして、畳み込みフィルタやプーリングによる重みなどを最適化することによって学習が行われます。このパラメータの最適化を効率的に行うテクニックとして、代表的なものに活性化関数を使う手法があります。具体的にはフィルター適用後の画像データに活性化関数(ReLU: Rectified Linear Unit)を適用するという手法です。
活性化関数(ReLU)とは、0未満の出力値をすべて0にする関数で、ある閾値以上の部分だけを意味のある情報として次の層に送る働きをします。畳み込みフィルターや全結合層の後に置かれ、抽出された特徴をより強調する働きがあります。
畳み込みとプーリングとその間のReLUなどの活性化関数という組み合わせを何層かに重ねることで、入力層に近いところでは今述べた微細な特徴を表現し、入力層から遠い層では全体的な特徴を表現できるようになります。
その過程で得られたものを全結合により推測を行う層(全結合層)へと渡して、最終的に分類を行うというのがCNNによる画像認識の手順になります。

図6:CNNの処理の全体像
CNNでできること
CNNでできることは大きく分けて2つあります。それぞれについて解説していきましょう。
- 画像認識
- 画像生成
1. 画像認識
CNNでは、画像認識ができます。画像認識が注目されたきっかけとして、2012年に開催されたILSVRCという画像認識のコンペがあります。
2011年以前のコンペでは画像認識のエラー率が26%〜28%で推移しており、「どうやって1%エラー率を改善するか」という状況でした。しかし、2012年にCNNを活用したチームがエラー率16%を叩き出しました。文字通り桁違いの精度です。
2012年の優勝モデルが画像認識タスクのデファクトスタンダードとして利用されるようになり、その後もこのコンペではCNNを使ったモデルが優勝し続け、現在では人間の認識率を上回る精度を実現しています。そして、このコンペをきっかけにディープラーニングを使ったシステムが大いに注目されるようになりました。
2. 画像生成
CNNでは画像生成もできます。
例えば、
- 白黒写真の色付け
- 鳥や犬などの画像の作成
などができます。なぜCNNで画像生成ができるかというと、CNNを活用することでより複雑な特徴を学習できるからです。
具体的には、CNNは画像の線や色合いといった簡単な特徴だけではなく、画像の模様のようなやや複雑な特徴や、犬の顔や鳥の足というような複雑な特徴まで学習することが可能です。
低レベル特徴〜高レベル特徴の例
- 低レベル特徴:線や色
- 中レベル特徴:模様
- 高レベル特徴:犬の顔、鳥の足
その他にも、次のようなタスクが可能です。
- ラフスケッチの自動線画化:ラフスケッチに対して線を描き足してきれいな線画にするタスク
- 画風転写:画家の画風を他の画像に反映させるタスク
- 物体検出:画像の中から特定の物体を検出するタスク
- セグメンテーション:画像の中から特定の物体を切り出すタスク
まとめるとCNNは画像を使うタスクであれば、応用範囲はかなり広い技術であると言えます。
まとめ
今回は、主に画像認識や画像生成のタスクで活用されているCNNについて解説しました。簡単に言えば、畳み込み演算とプーリング+活性化関数を活用した特徴の強調を繰り返すことで、画像の部分的な特徴と全体的な特徴を学習していき、画像の特徴量の学習を最適化していくネットワークです。
このように、画像を2次元データとして捉えて、特徴を学習する手法が用いられ始めたことで画像認識の精度は向上し、応用の範囲も格段に広がりました。
具体的には下記のような用途に活用できます。
- 画像認識(例:犬の顔などを見分けるなど)
- 画像生成(例:白黒画像からカラー画像へ変換するなど)
- 画風の再現(例:持っている写真をモネ風のタッチに変換するなど)
- 物体検出(例:道路の写真から車だけ抽出するなど)
- セグメンテーション(例:草原の画像の中からシマウマの輪郭だけを切り取るなど)
- デッサンの線を描く(例:鉛筆の軽いタッチのでデッサンの線を太くするなど)
このように、画像で何かしたい場合、CNNを活用すれば大体のことが実現できるという状況になっています。そのため、画像の活用に関して自由な発想でアイデアを出し、業務や研究等で活用していく姿勢が求められます。汎用性の広い技術なので、どんな用途で活用できそうかぜひ考えてみてください。
CNNのネットワークのよい細かい内容や実装方法に関してより詳しく知りたい方は専門書やオンライン講座などで知識を深めることをおすすめします。KerasやPyTorchなどでCNNを使うための知見が公開されているので、実装したい方はこれらのライブラリを活用してみてください。