
自然言語処理は、数あるディープラーニングの活用先の中でも有力な選択肢になっています。さらに、自然言語処理のような文章を扱う技術のニーズは年々高まっています。この機会に、自然言語処理についても理解していきましょう。
この記事では、自然言語処理で何ができるかを知りたい、業務で自然言語処理を活用してみたい、実際に自然言語処理を始めてみたいという方に向けて、ディープラーニングを活用した自然言語処理について紹介します。
自然言語処理とは
自然言語処理とは、人間が日常的に使っている自然言語をコンピュータに処理させるための一連の技術です。まずは、自然言語処理の応用例について解説していきます。
文章分類
文章分類とは、入力された文章の性質を判断するタスクです。例えば、次のようなものがあります。
- 入力した文章がポジティブな内容かネガティブな内容かを判断するタスク
- 問い合わせかコメントか文章の種類を分類タスク
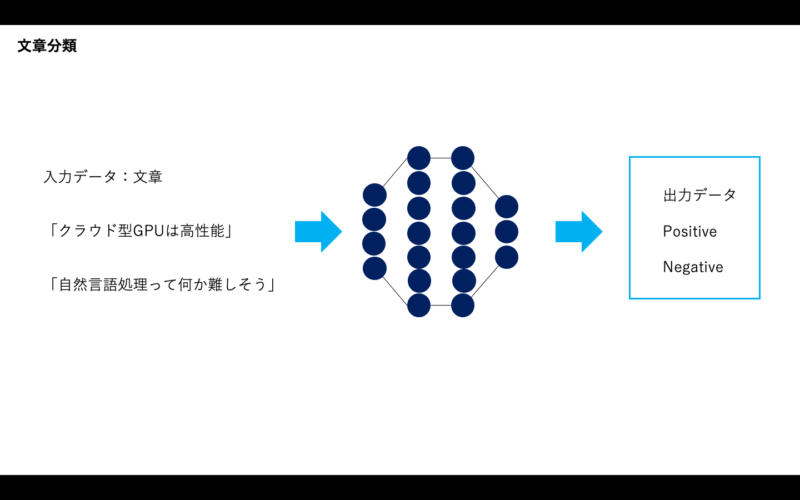
- 「クラウド型のGPUって便利」という文章があったらPositiveと判断
- 「自然言語処理って難しそう」という文章があったらNegativeと判断
このように判断するイメージです。
系列ラベリング
系列ラベリングとは、文章内の語句にラベルをつけるタスクです。例えば、次のようなタスクがあります。
- 入力されたデータからメーカーや商品名を抜き出すようなタスク
- 入力文章の品詞を見分けるタスク
「クラウド型GPUはMorgenrotのM:CPPがおすすめです」という文章があった場合、
- 会社名:Morgenrot
- 製品名:M:CPP
とするようなイメージです。
文章補完
文章補完とは、文章の空白を推定するようなタスクです。例えば、文章中に空欄があった場合、その空欄が何かを推定して埋めてくれます。
「Deep Learning成功には〇〇が必要です」という文章があったら、「Deep Learning成功には高性能コンピュータが必要です」と埋めてくれるようなイメージです。
音声認識/音声合成
音声認識/音声合成とは、音声を入力として、文章を出力するタスクです。音声で「こんにちは」と話しかけると、文字で「こんにちは」と出力されたり、その逆に文字でこんにちはと入力すると、音声で「こんにちは」と出力してくれるイメージです。
翻訳
翻訳とは、多言語翻訳のように文章を別の文章に翻訳するタスクです。「This is GPU」という英語の文章があれば、「これはGPUです」と言う日本語を返してくれるイメージです。
画像キャプショニング
画像キャプショニングとは、文章から画像に生成するタスクです。例えば、犬が3匹写っている画像があれば、「犬が3匹写っている画像です」という文章を出力します。
感情分析
感情分析とは、文章分類を感情分野に対して特化したようなサービスです。具体的には、次のような用途で活用できます。
- 感情強度の分析
- 修飾表現の豊富さ
- 話し言葉への対応
例えば、
「クラウド型GPUは便利」という文章があったとすると、【感情要素:便利(+1)】となり、全体スコアは+1となります。
「クラウド型GPUはとても便利」という文章があったとすると、【強調表現:とても(×2)】【感情要素:美味しい(+1)】となり、全体スコアは+2となります。
このように、感情の要素や強調表現などを数値化することで、感情強度を分析できます。感情分析ができることで、自然言語処理がマーケティングなどに活用ができます。
例えば、ECサイトの商品レビューや掲示板に書き込まれた新しいスマホへの感想など、Web上への書き込みから、そのコメントの感情を読み取ることで、商品開発やマーケティングなどに活かせるのです。
自然言語処理の仕組み
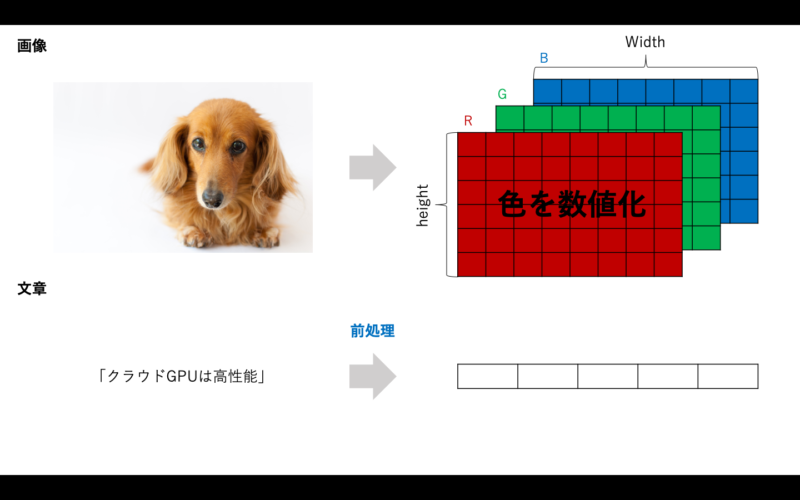
次に自然言語処理の仕組みについて紹介していきます。自然言語処理はまず最初に文章を数値化する必要があります。この文章の数値化が、画像認識モデルを作る場合と比べて複雑になります。
なお、画像認識で使われる「CNN」に関して詳しく知りたい方は、こちらを確認してください。
なぜ画像認識より複雑かというと、画像はRGBのように三原色を基にして色を数値化する手法があるため、画像をそのまま数字にするのは容易ですが、文章の場合はそのまま数字に変換ができないからです。そのため、自然言語処理の場合は自然言語処理特有の前処理が必要になります。
入力データの準備
まず前処理を行い、入力データを準備する必要があります。説明のために、さきほど文章分類で紹介した図をもう一度見てみましょう。
自然言語処理では、この図に書いてある「クラウド型GPUは高性能」や「自然言語処理って何か難しそう」のような文字列を前処理によって数値化していく必要があります。
そのための手法について解説していきます。前処理は次の手順になります。
- 入力文章を単語へ分割する
- データセット内に含まれる単語を列挙する
- 単語をIndex化する
- 入力文章を単語Indexの系列で表現する
- データの長さを揃える
順に解説していきましょう。
Step1:入力文章を単語へ分割する
まず、最初に入力する文章を単語毎に分割します。具体的には、
- 「クラウド型GPUは高性能」→‘クラウド’,’型’,’GPU’,’は’,’高’,’性能’
- 「自然言語処理って何か難しそう」→‘自然’,’言語’,’処理’,’って’,’何’,’か’,’難し’,’そう’
といったように、文章をそれぞれの単語に区切ります。
Step2:データセット内に含まれる単語を列挙する
次に、データセットに含まれる単語を列挙していきます。
Step3:単語をIndex化する
続いて、単語をIndex化(数値を付与)していきます(※EosはEnd of Sentenceの略で文章の終わりを表す記号です)。

Step4:入力文章を単語Indexの系列で表現する
データセットに数値を振ったら、文章を区切った後の単語列を付けます。
Step5:データの長さを揃える
次に、データの長さを整える処理を行います。基本的に、自然言語処理の際もデータの長さが揃っていた方が精度が上がります。
そのため、単語にIndex化した数字列の後に「0」をつけることで、データの長さを揃える処理をします。これが「0 padding」という処理です。

ディープラーニングが自然言語処理に向いている理由
ディープラーニングを自然言語処理で活用ことによるメリットは、従来の自然言語処理よりも複雑な処理ができるようになったことです。
従来の自然言語処理では、単語を一つひとつ別のトークンと認識していました。これはディープラーニング以前は大量のデータを処理して解析するということが難しかったため、先ほどの前処理の例のようにあくまで単語を数値化して、コンピュータに読み込ませるという単純な処理にとどまっていました。
しかし、データ量の増加やコンピュータの性能向上によってディープラーニングを活用できるようになり、より複雑な言語処理が可能になってきています。
ここからは、自然言語処理とディープラーニングが相性が良い理由について紹介していきます。
理由①:単語間の距離を認識できるから
自然言語処理にディープラーニングを活用することによって、単語同士がどのように関連しているかを分析することができるようになりました。例えば、「柴犬」と「チワワ」という単語があった場合に、従来の自然言語処理の手法だと、「柴犬」と「チワワ」は別物のトークンという認識になっていました。
ディープラーニングでは、この単語をベクトル上の距離として認識することができるようになりました。例えば、柴犬と車の距離が3だとすると、柴犬と車の距離が10といったように、それぞれの単語の距離を数値化することができます。
さらには、単語間の関係性を距離で認識することもできるようになりました。例えば、「東京」と「日本」は首都と国の関係と認識し、「ワシントンDC」と「アメリカ」の場合と非常に類似した符号であると認識できます。
このように、ディープラーニングでの学習は単語毎の関係性を把握しながら知識を増やしていくので、人間の母国語の理解に近いような自然な学習方法になっています。単語をベクトル上でマッピングできるようになり、自然言語処理は発展しました。
そして、ディープラーニングを活用した自然言語処理はマーケティングにも活用されています。
例えば、以前であればPRや宣伝の際に押さえておくキーワードを手動で集めていました。しかし、最新の自然言語処理では、キーワードの類似性を分析することで、PRや宣伝に必要なキーワードを自動で抽出できるようになりました。キーワードのベクトル上での類似度がわかることで、より適切でスピーディーなマーケティングの実施が可能になってきているのです。
理由②:文章作成や段落分けができるから
ディープラーニングを使った自然言語処理で、文章の作成や段落分けなどの処理を行えるようにもなりました。文章作成や段落分けなどの処理に関しては、キーワードの抽出よりも難しく、現状では発展段階です。ただ、今後徐々に可能になっていく分野ではないかと考えられます。
理由③:将来的には記事作成など長い文章の作成もできるから
将来的には、記事作成などの長い文章の作成ができる可能性もあります。単語→段落→記事のように、より複雑度の高い文章の処理を行うための技術が日夜研究されています。今後の技術動向から目が離せない分野です。
自然言語処理の活用例
ディープラーニングを活用した自然言語処理は、さまざまな場面で応用されています。ここからは、具体的な活用例について紹介していきます。
翻訳分野での活用例(文章翻訳)
翻訳分野では、「DeepLGmbH」のDeepLというサービスがあります。2020年3月に中国語や日本語への対応が始まり、既存のGoogle翻訳などの翻訳ツールより高い精度の翻訳文を作成できるということで話題になりました。
翻訳分野での活用例(音声翻訳)
音声翻訳の分野では、中国の企業のAIed社の「CHIVOX」というサービスがあります。アプリに向かって英語を話すことで、正しい発音かどうかをチェックしてくれるサービスです。
これは、英語スピーキング評価を行うAI技術で、既に世界132ヶ国で導入されており、日本でも利用されています。このアプリを使うことで、発話が流暢かどうかなどを評価することができます。「チャイルドモード」「ノーマルモード」「ネイティブモード」という3種類のモードを持っていることで、幅広い英語力に対応できます。
小売分野での活用例
小売業での自然言語処理の活用は主に、チャットボットなどの顧客接点をAIに任せるという切り口で進んでいます。例えば、SPJ社の人工知能接客システムでは、次のようなことを行えます。
- 顧客ニーズのヒアリング
- 顧客ニーズから統計解析した、顧客ごとに最適な商品の提案
- 受注業務
- 業務システムと連携した業務(売れ筋商品の提案、在庫確認、入荷予定確認、セット商品の大安、過去に顧客が購入した商品の注目履歴確認、過去に購入した商品の傾向から解析した各顧客に最適な商品の提案等)
- 多言語対応業務
このように、店舗での接客のような分野に関しても自然言語処理が活用されています。
他には、従来の自然言語処理の応用分野である文章上での対応も行っています。具体的には、カスタマーサポートのためにチャット上での自動応答を担当するようなケースが多いです。
医療分野での活用例
医療分野での自然言語処理の活用は主に下記の2種類に大別されています。
- 医療データの整理・管理
- 診断の支援
まず、医療データの整理・管理は、医療機関が抱えている大量の医療データを病名やキーワードで整理することで、病名と症状の間の関係が明らかになり、それぞれの関係を参考にすることでより高精度な診断ができるようになります。
医療データが整理されることで、結果として診断の支援になります。有名な例だと、Amazon Comprehend Medicalのようなサービスがあります。
あらかじめ学習した疫病名、薬の名前などの医療用語に基づき、問診票のような医療データを整理・分類することができます。具体的には、生体組織、状態、手順、薬、略語などの膨大な語彙を基に選別ができます。
さらに、詳細な連絡先や医療登録番号等を見つけることができるAPIも提供されています。医療データの整理・分類を行えば、例えば、ある薬の効果について過去のデータを参照したいときに、投薬料や投薬頻度と言った属性に基づいて整理することができます。
法務分野での活用例
法務の分野では、膨大な量の文章を扱います。そのため、自然言語処理の導入で効率化される業務として期待されています。
例えば、LawFlowの「LawFlow」のようなAI自動契約書チェックサービスなどがあります。このサービスでは、次のような契約書締結のために必要な機能が、自然言語処理でサポートできています。
- AIが契約書の全文書を自動でチェックしリスクや必要な条文を教えてくれる機能
- 検出したい条項を自分好みに設定できるカスタマイズ機能
- ひな形契約書データと対比で新規条項を差分表示するひな形機能
マーケティング分野での活用例
自然言語処理はマーケィングの分野でも活用されています。例えば、ジェットラン・テクノロジーズ株式会社のTrueTextなどがあります。
主に感情分析を利用し、話し言葉の解析や、商品名やサービス名などの固有名詞などの分析を行い、自社商品に対するネット上での書き込みを解析することで、自社製品が市場に受け入れられるかなどを分析することができます。
感情強度の分析を行っていることはもちろん、他にも言語の幅の広さに対しても対応ができています。例えば、「めっちゃ」「すごい」「とても」などの幅広い修飾イベントへの対応なども行います。
他にも、Web上には「文語」と呼ばれる文法的に正しい文章以外にも、くだけだ「口語」のような表現もあります。例えば、「美味しくねぇ」「美味しくないねー」といったように、微妙にニュアンスが違う、話言葉がたくさんあります。自然言語処理を活用すると、このような「話し言葉への対応」への対応もできるようになってきています。
まとめ
ディープラーニングを活用した自然言語処理の活用例や仕組みなどについて解説しました。自然言語処理の活用方法に関してイメージ持って頂けたことでしょう。
自然言語処理で十分な精度を行う場合は、十分なデータ量が必要です。単語や文章などの言語はパターンが多いため、AI最適化のための大量のデータが必要になります。AIの最適化の結果は、与えられたデータ量の応じて異なります。
ビジネス上で有効なモデルにするためには、あらゆる状況に臨機応変に対応できるモデルになるので、少量のデータしか入力していない場合は、限られた状況にしか対応できないモデルとなってしまいます。
さらに、人間の行動や言語は不特定多数の要素から影響を受けるため、特定の要素に関する情報の「量」だけでなく、情報の「種類」も増やしていく必要があります。このように、自然言語処理は画像認識などよりもデータ量が必要になります。
大量のデータ量が必要となるため、ディープラーニングで自然言語処理を行う場合は、高性能なコンピュータが必要になります。そこでディープラーニングに必要な計算資源を確保したいという場合は、クラウド型のGPUを利用することがおすすめです。
クラウド型のGPUがおすすめである理由は、大きく分けて3つあります。
- 低コストで迅速な運用ができる
- 容易にリモートワークでの運用ができる
- AI技術を身近に利用できる
まずクラウドGPUは、オンプレミスのGPUと比較して低コストでの運用が期待できます。
例えば、オンプレミスのGPUを使う場合は、導入の初期費用や環境の移行のコストに時間がかかってしまいます。クラウド型であれば、必要なときに必要な分だけGPUリソースを確保できるため、初期費用を抑えられると同時に即日利用ができるなど、スピード感を維持した運用が実現します。低予算での開発とスピードを重視する場合はクラウド型GPUは最適な選択肢と言えます。
また、クラウドGPUは、ネット環境があればどこでもいつでも使えるため、リモートワークでも運用がしやすいです。
オフィスでのサーバーが不要であるため、何らかの災害が発生した際にも事業を継続できます。そのため、BCP(Business Continuity Planning:事業継続計画)対策の上でも有効です。
このように、予算や場所の制約が少ないクラウドGPUを活用することで、AIなどの最新テクノロジーを利用しやすい環境になりました。初期投資や環境のアップデートが進められなかった現場でも、クラウドであれば最低限のライセンス料金で利用が可能になります。
そして、クラウドGPUの中でも、シンプルでカスタマイズが自由な「M:CPP」がおすすめです。M:CPPを活用すれば、「大規模な開発を進めていく前に、一度コストを抑えてテストを行いたい」「オンプレミスのGPUの維持管理コスト負担が気になる」など、GPUの運用に関する課題を一気に解決することが可能です。

大手GPUクラウドと比べても低価格であるため、費用に悩んでいる場合も、M:CPPであれば最適化とオールインワンパッケージの採用により、さらなるコスト削減を期待できるでしょう。M:CPPに関しては、こちらのホームページを参考にしてください。