
ニュースや記事でよく目にする「ディープラーニング(Deep Learning)」ですが、社会やビジネスにどのような影響を与えていて、どのように活用されていくのか興味があるが、実際よくわからないという方も多くいるのではないでしょうか?
この記事では、ディープラーニングの概要やできること、注目されている理由、最近のトレンドと活用事例についてわかりやすく解説します。
ディープラーニングとは
まずは、ディープラーニングとは何かについて簡単に紹介していきましょう。ディープラーニングとは、十分なデータ量があれば、人間の助言なしで自動的にデータから特徴を抽出してくれる学習のことです。
これだけだとわかりにくいので、詳細については「ディープラーニングの仕組み」のところで解説します。
ディープラーニングが注目されている理由(2012年以降)
ディープラーニングが注目されたきっかけが、2012年にILSVRCという画像認識のコンペにおいて、ディープラーニングを使ったチームが優勝したことです。
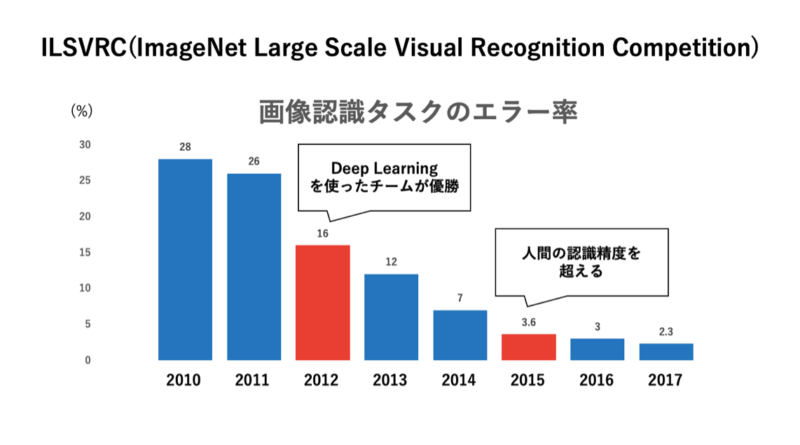
図1:画像認識コンペの優勝チームの成績
ディープラーニングが出てくる以前は、AIに画像認識をさせること非常に難しいと考えられていました。実際、2011年以前は人間が細かい調整を行い、1%~2%の精度向上を目指すのがやっとという状況でした。
しかし、2012年にトロント大学のヒントン教授のチームがディープラーニングを活用して 一気に10%近くの精度向上を達成しました。これ以降、ディープラーニングを活用してコンピューターに画像認識を行ってもらう取り組みが一気に広がり、結果としてAIに対して大きな注目が集まりました。
ディープラーニングの精度が向上した背景
ディープラーニングの精度が向上した背景としては次のようなことが挙げられます。
- アルゴリズムの進化
- データ量の増加
- コンピュータの計算の性能の向上
CNN(Convolutional Neural Network:畳み込みネットワーク)やRNN(Recurrent Neural Network:再起型ネットワーク)といった、新しいアルゴリズムが出てきたことや(後で個別に詳しく解説します)、WebやSNSの発展で大量データ(ビッグデータ)を収集できるようになったことがあります。
GPUなどの登場によってコンピュータの計算の能力の向上したことなどが重なり、ディープラーニングで高い精度が出せるようになりまた。もちろん、アルゴリズムが改良されたことも大きいですが、どちらかというとデータ量の増加とコンピュータの性能の向上の方が影響しています。
Googleの猫とAlphaGo(2012年〜2017年)
画像認識の精度が上がったことで、Googleを中心に、大量の計算資源を活用して新しいプロダクトを出す取り組みが盛んに行われました。
2012年にはGoogleの猫というプロジェクトが行われ、16,000のプロセッサーと10億ものコネクションによるネットワークを活用し、猫の画像をコンピュータに認識させることに成功しました。
2017年にはGoogleの子会社であるDeep Mindを開発したAlphaGoが、世界王者の柯潔(かけつ、中国の囲碁棋士)に勝利しました。Alpha Goの進歩のためにも膨大な計算資源が活用され、プロセッサ数がCPUサーバを1,202個、GPUサーバを176個という物量作戦で、囲碁の王者を圧倒しました。
ディープラーニングとAI・機械学習の違い
人工知能(AI)について調べていると、「AI」「機械学習」「ディープラーニング」といった用語が出てくることでしょう。では、それぞれどう異なるのでしょうか?概念の広さは、「AI>機械学習>深層学習」となります。
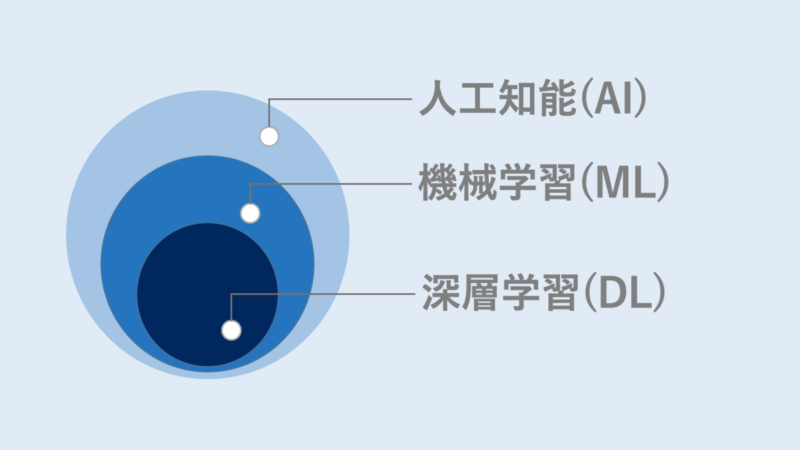
図2:人工知能(AI)と機械学習(ML)と深層学習(DL)
人工知能(AI)
人工知能は、とても広い概念の言葉です。なので、専門家の間でも共通の定義はありません。ここでは、AI研究の第一人者である東京大学の松尾豊教授の定義を借用します。
- 人工知能:人工的につくられた人間のような知能、ないしはそれを作る技術
つまり、コンピュータに人間のような知的処理を行わせる取り組みを含んでいる概念ということです。
機械学習(ML)
機械学習のパイオニアであるアーサー、サミュエルによると、機械学習とは、“明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野”(“Field of study that gives computers the ability to learn without being explicitly programmed”Arthur Samuel(コンピューターサイエンティスト))とされています。例えば、機械学習では分類問題や回帰問題を解くことができます。
ディープラーニング(DL)
ディープラーニングとは、十分なデータ量があれば、人間の助言なしで自動的にデータから特徴を抽出してくれる学習です。人間の助言なしで、自動的にデータから特徴を抽出してくれるという点がポイントです。
ディープラーニングの革新性を理解するために、画像認識がコンピュータにとって難しかった理由について紹介していきましょう。そのために、「構造化データ」と「非構造化データ」について紹介します。
- 構造化データ:表計算などに整理されているデータ
- 非構造化データ:テーブル形式で整理されていない生データなど
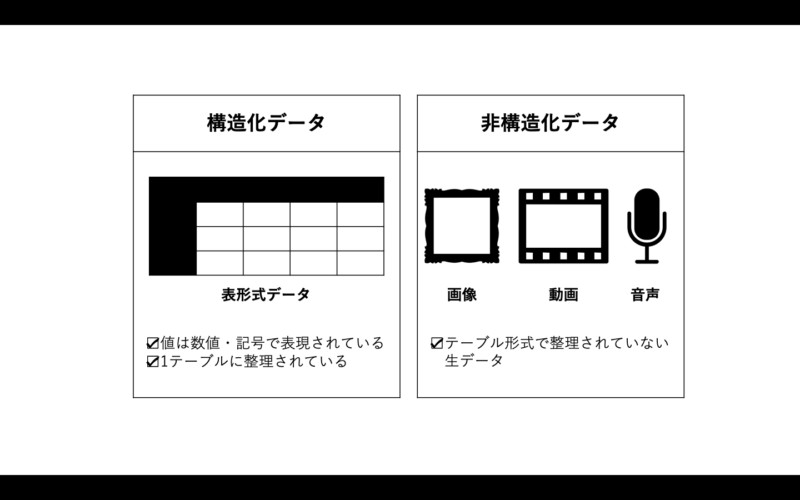
図3:構造化データと非構造化データ
機械学習では、データを学習させる際に、人間がデータテーブル形式などにして、整理する作業が入りました。
しかし、画像などの生データは人間がテーブル形式などにして整理することは困難です。そのため、ディープラーニングが登場する以前は、画像の特徴をコンピュータに教える手法がなく、AIで解けない問題として有名でした。
ディープラーニングの一分野である「畳み込みニューラルネットワーク(CNN)」という画像の特徴を学習する手法が開発されたことと、膨大なデータを高性能なコンピュータで計算するGoogleなどの企業が現れたことで、非構造化データでも自動でコンピュータが特徴を学習し、画像を認識できるようになりました。これが、ディープラーニングの人間の助言なしで自動的にデータから特徴を抽出しているという機能です。
ディープラーンングの仕組み
ここからは、ディープラーニングの仕組みについて具体的に紹介していきます。ディープラーニングは、別名「ディープニューラルネットワーク」と言われるように、ニューラルネットワークというアルゴリズムの層を深くしたものです。
まずは、ニューラルネットワークの仕組みから紹介しましょう。
ニューラルネットワークとは
ニューラルネットワークの歴史は1943年に遡ります。
1950年代の第一次AIブームで、パーセプトロンというニューラルネットワークが注目を集めました。脳を模したモデルが開発されたとして話題になりましたが、線形分離不可能な問題が解けないという弱点が明らかになり、下火になりました。
1980年代の第二次AIブームでは、マルチレイヤーパーセプトロンというモデルが注目を集めました。しかし、1980年代はWebやインターネットが登場する前です。当時は、機械学習に利用可能なデータが少なかったため、**多層ニューラルネットワークの学習精度がなかなか向上しないなどの問題から、ブームはまた下火に向かいました。
そして、今回の第三次AIブームでは、2006年に開発された「オートエンコーダ」という技術により、ニューラルネットワーク自身で特徴を捉えることが可能になりました。オートエンコーダと多層ニューラルネットワークを用いた学習方法は「ディープラーニング」と呼ばれ、3回目のAIブームのブレイクスルーとなり、現在に至っています。
パーセプトロン
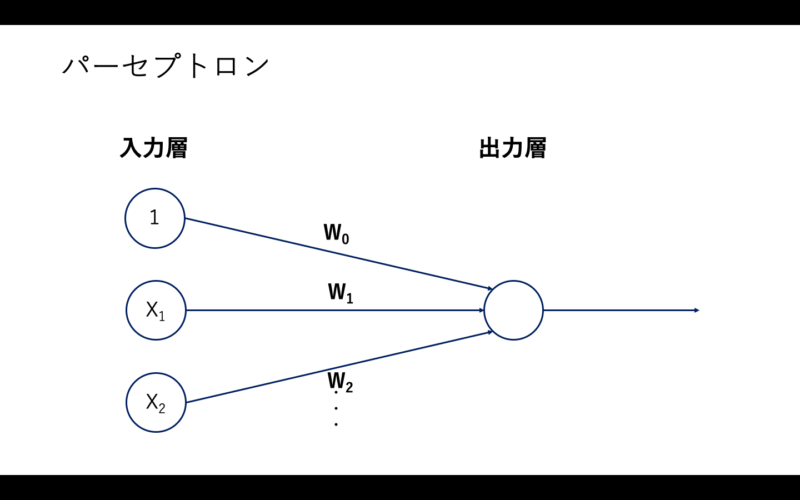
図4:パーセプトロン
パーセプトロンでは、まず入力層にデータを入力し、そのデータを認識するための特徴量を入力します。その入力に対して、ニューロン間のつながりの強さを示した重みw1、w2……を掛けたものを、出力層のニューロンに入力します。
そして、出力層のニューロンで、この入力を足し合わせたものを”活性化関数”に通し、最終的な結果を出力します。
この原理をわかりやすく二次元で考えてみます。
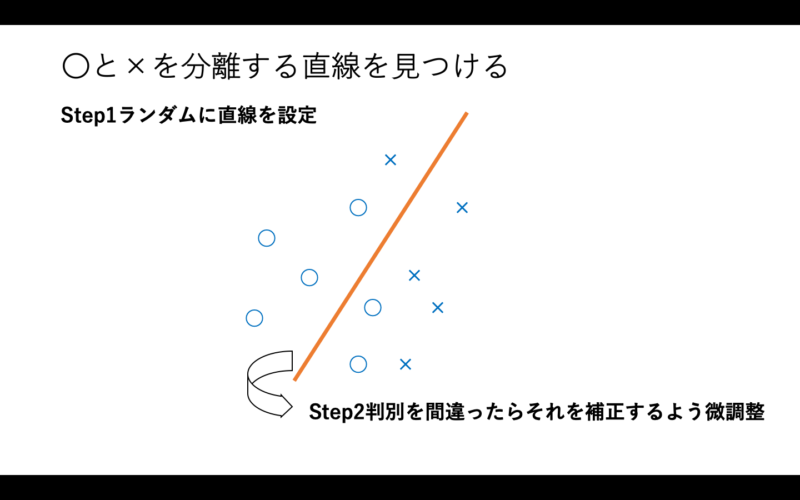
図5:パーセプトロン
〇と×を分類するための直線をランダム線に配置し、ここは違うから少し動かす、そしてまた違うから動かす、というような微調整を繰り返していきます。これを正しく学習させる、もしくは、上限の回数を設定し上限に到達するまで学習を繰り返すことで、正答率を上げていきます。これがパーセプトロンの仕組みです。
しかし、今回の例なら、直線を引けば分けられそうですが、実際には直線で分類できなそうな問題もたくさんあります。そのため、複雑な分布を持つ(線形分離不可能な)問題について適用ができませんでした。
マルチレイヤーパーセプトロン
2回目でのAIブームを牽引したのは、パーセプトロンの「入力層」と「出力層」の間に「隠れ層」を取り入れ、多層にした「マルチレイヤーパーセプトロン」です。パーセプトロンには実現できなかった非線形分類も可能になり、複雑な処理ができるようになりました。
マルチレイヤーパーセプトロンには「誤差逆伝播法」という方法が使われています。
- 誤差逆伝播法:複雑な数式を分解し、シンプルな問題の組み合わせにしていく方法。その際、最後の数式を最適化し、次の最適化したものを最適化と、後から順に解いていけば容易に最適化(微分)ができます。
しかし、微分を繰り返すことにより、誤差がコンピュータの認識範囲を超え、「誤差がない」と判断してしまう「勾配消失問題」が発生し、学習がうまく進まなくなりました。
さらに、当時は層を3層以上と複雑にしていくことで、学習データに適合しすぎてしまい、学習データと異なるデータでは、正答率が低くなる「過学習」が発生しました。このような欠点を解消できず、2回目のAIブームも下火になりました。
ディープラーニング
そして、今回の3回目のブームを牽引しているのが「ディープラーニング」です。2回目のブームまでは、入力層に人間が指定した特徴量を入力していました。しかし、ディープラーニングでは、層を複数にすることで、特徴量をコンピュータが判断できるようになりました。
画像の判断などの際に、何を特徴とするかをディープラーニングが自動的に学習できるようになり、人間が考えた特徴量よりも認識精度が高くなりました。精度が上がった反面、コンピュータが特徴量を判断するため、出力の根拠がわからず、ブラックボックス化してしまうという欠点もあります。
ディープラーニングでできること
ディープラーニングの登場によって、特徴量をコンピュータが自動で学習できるようになり、人間よりも精度の高い画像認識精度を実現することができました。画像認識でのブレークスルーをきっかけに、AIへの注目や投資が集まり、画像認識以外の分野でもさまざまな研究開発が行われました。
ここでは、ディープラーニングで代表的な4つの手法を紹介します。
CNN(画像認識)
Convolutional Neural Network(CNN)は、主に画像認識の分野で使われる手法です。「畳み込み層」と「プーリング層」という二つの特殊なレイヤーを持ったニューラルネットワークです。
CNNでは、畳み込み層で画像内の特徴を発見し、プーリング層で抽出された特徴を集約しています。この2つの処理が繰り返されて、画像認識が行われています。
読み込む画像内に特徴が多いほど、特徴を発見するための計算も必要になります。そのため、従来のコンピュータには処理が困難でした。ですが、CNNに組み込まれているReLUという活性化関数を導入したことで、精度が向上したのです。
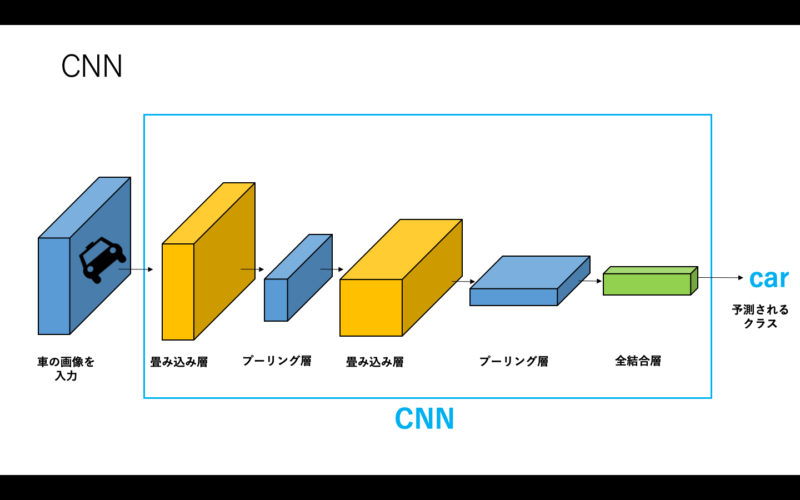
図6:CNNの概念図
RNN(時系列データ)
Recurrent Neural Network(RNN)は、音声の波形や動画、文章(単語列)などの時系列データを扱うニューラルネットワークです。CNNの扱う画像データと違い、音声データなどの時系列データを扱います。
このような時系列のデータをニューラルネットワークで扱うため、出力側から入力側へフィードバックがあるのが特徴です。
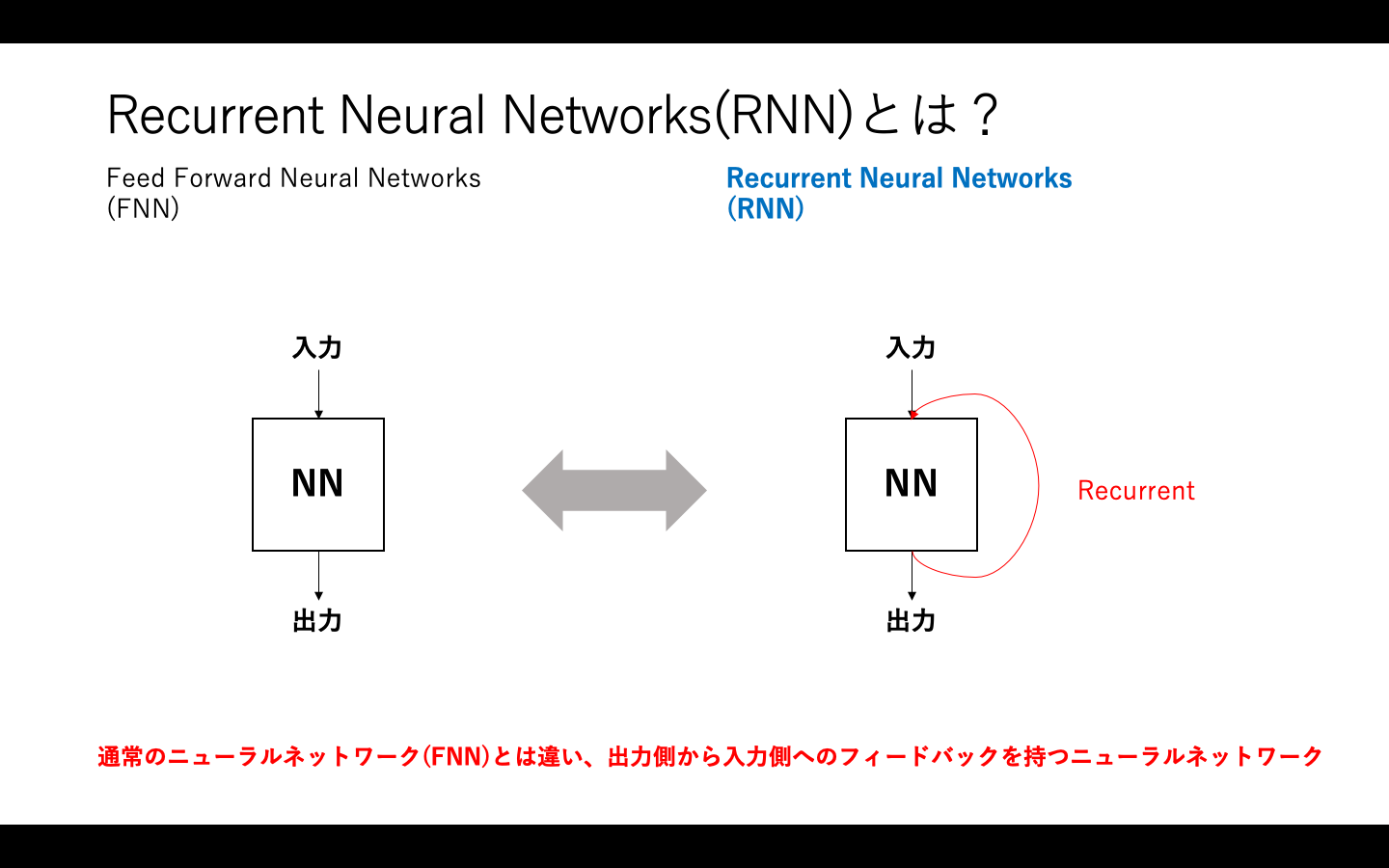
図7:RNNの概念図
フィードバックがあることで時系列を意識した認識が可能となり、精度が上がります。
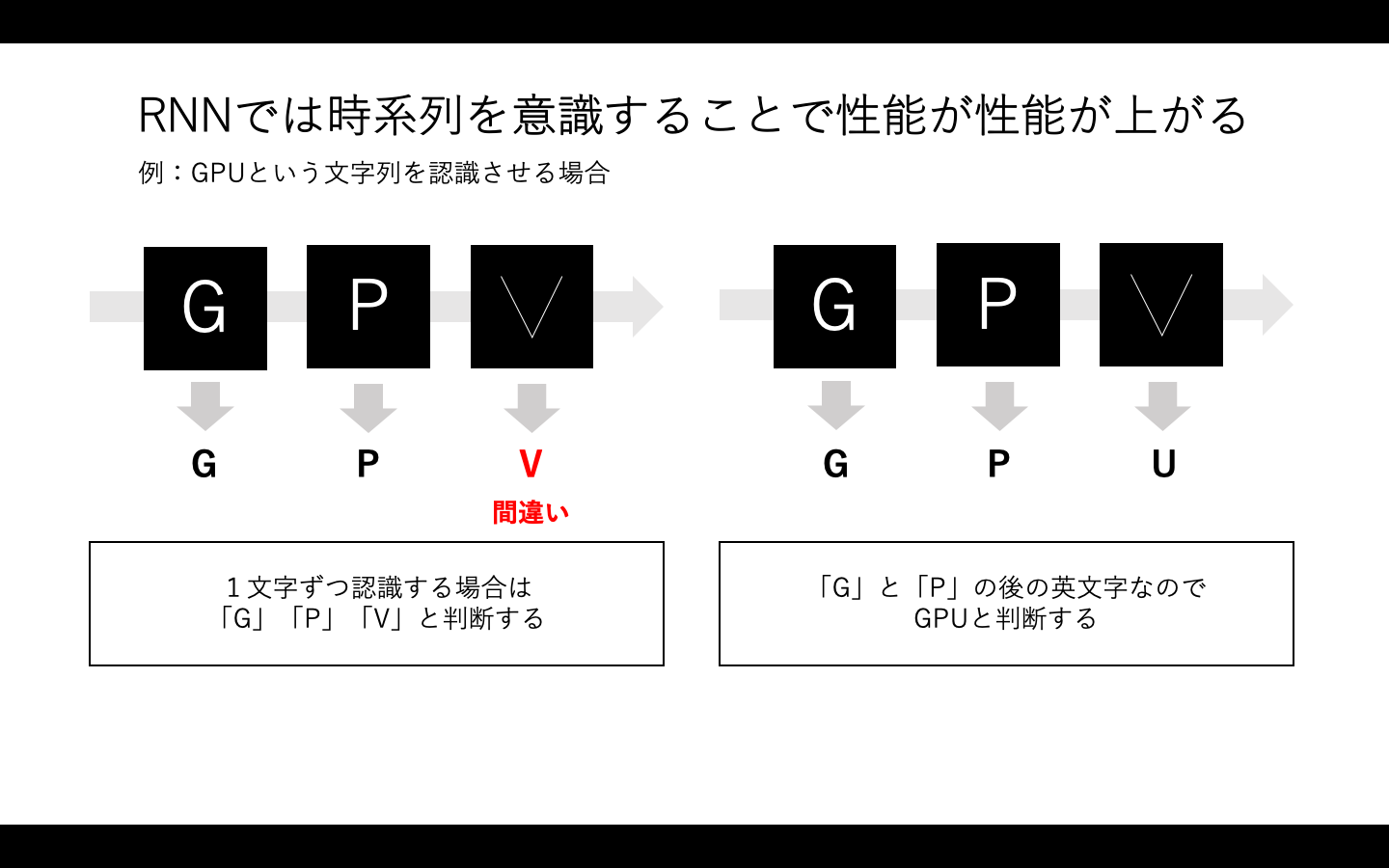
図8:RNNで文字列の認識
上の例で考えてみましょう。
コンピュータに3つの文字を認識させようとします。
左側の通常のニューラルネットワークでは「G」と「P」と「最後の文字」を1文字ずつ認識するので、3文字目を「V」と認識する可能性が高くなるでしょう。
右側のRNNでは前後の文字を意識するため「G」「P」の後にくる文字であれば「U」の可能性が高いと判断します。
このようにニューラルネットワークに時系列を意識させることで、精度を上げていこうとするアイデアがRNNです。
RNNは、長時間前のデータに利用しようとすると、誤差が消滅したり演算量が爆発するなどの問題があり、短時間のデータしか処理できませんでした。
LSTM(時系列データ+忘却ゲート)
LSTM(Long Short-Term Memory)は、RNNの欠点を解消し、長期の時系列データを学習できるモデルです。発表は1997年と20年以上前ですが、ディープラーニングの流行とともに注目され始めたモデルです。
LSTMでは、「隠れ層」の構造を発展させ重要なデータを残し、不要なデータを忘れさせることができるようになりました。また、LSTMには学習状況を保存できる「メモリセル」というメモリや、「入力ゲート」と「出力ゲート」の間に「忘却ゲート」を加えることで、長期的な学習も可能にしました。
LSTMは自然言語処理に応用され、大きな成果を上げ始めています。
GAN(画像生成)
GAN(Generative Adversarial Network)には、Generator(生成器)とDiscriminator(識別器)という2つのネットワークがあります。
Generatorは、教師データと同じようなデータを生成しようとします。一方、Discriminatorは、データが教師データから来たものか、それとも生成モデルから来たものかを識別しようとします。
GANの基本的な考え方は、偽札作りと警察の関係で例えるとわかりやすいです。偽札作りと警察官の2名がいたとしましょう。偽造者は、本物の紙幣と似たニセ札を造ります。警察官は、ニセ札を見破ろうとします。
下手なニセ札は簡単に警察官に見破られますが、偽造者の腕が上がって精巧なニセ札になっていくと、警察官もなんとかニセ札を見破ろうと頑張って見分けようとします。
お互いに切磋琢磨していくと、最終的にはニセ札が本物の紙幣と区別がつかなくなっていきます。この関係をモデル化したものが、下の図です。
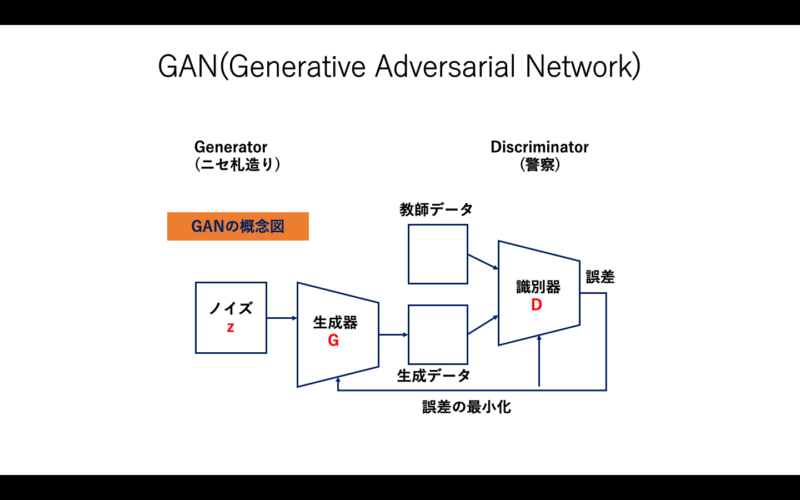
図9:GANの概念図
生成器G(Generator)と識別器D(Discriminator)の2つのニューラルネットワークで構成されています。生成器が偽造者で、識別器が警察官の役割です。
ディープラーニングのトレンド
一通りディープラーニングの主要なモデルを紹介しました。ここからは、ディープラーニングの最近のトレンドについて紹介していきましょう。
性能向上
ディープラーニングは、2015年の画像認識のコンペでエラー率3.57%というエラー率を記録し、人間の認識精度を超えました。さらに、2016年は2.99%、2017年は2.25%、2018年の2.4%では若干下がったものの、2019年は1.54%となり、2020年には1.3%までエラー率が下がりました。
年率50%に迫る精度の誤差の改善を達成し、人間を突き放している状況です。
NAS/AutoML
NAS(Nueral Architecture search)やAutoML(Automated Machine Learning)という理論が発展し、典型的タスクであれば、データを与えるだけで自動的にモデルを構築することが可能になってきています。従来は、入力データサイズの調整のための前処理やパラメーター調整が必要でしたが、モデル構築のために必要なのは学習用データと計算環境のみという状況になりつつあります。
End-to-end学習
ディープラーニングは、従来の機能開発の概念を変えています。従来は、現象や機能をモジュールに分解しプログラミングを行っていました。
例えば、手書き数字の認識なら「前処理」「画像特徴抽出」「判別分析」など、人手で各機能を分解してプログラムを書いていました。ディープラーニング以降は、データのみをもとに、機能全体を獲得できるようになってきています。
大規模化
モデルの大型化による超高性能・汎用モデルが実現されています。モデルのサイズは、2018年以降、毎年前年の10倍という急激なペースで巨大なモデルが作成されています。それに伴い必要な計算量も大幅に増加しています。
モデルの汎用化
さタスクごとのモデル学習から、大規模モデルによる複数タスクの対応へと軸足が移ってきています。例えば、自然言語処理であれば「文章分類モデル」「翻訳モデル」「対話モデル」などの各機能に分かれていましたが、今後はそれらを一つにまとめて「大規模言語モデル」という大規模モデルで複数タスクに対応するようになりつつあります。
このように、ディープラーニングは高精度・簡単・汎用によりより高度なタスクへの応用が加速しています。また、機能分解型の設計から、データドリブンなEnd-to-End学習による機能開発に発展しています。
Deep Learningにおいて、最終性能を決めるのは「データ」と計算能力になっています。各機能の個別開発から、大規模単一モデルによる複数機能を実現できるようになっています。
ディープラーニングの活用事例
最後に、ディープラーニングの活用事例を4つ紹介します。
画像翻訳
画像翻訳は、画像に自動で翻訳を行い、サイトを多言語化などを行う技術です。用途としては、Webサイトのコンテンツや、商品の紹介ページ、広告用のLP(ランディングページ)などを翻訳して、国外にもアプローチしたいと思った場合に活用できます。
自動で画像に外国語のキャプションがつくことで、日本語だけの場合よりも数倍〜数十倍の人たちを対象に情報を発信することができるようになります。
物体検出:空撮画像の認識
ディープラーニングは、物体検出として活用することもできます。例えば、ドローンで撮った空撮画像から、管理対象となる物体を自動で検出する取り組みも行われています。測量などの際に資材置き場や、工場現場の管理・監視を行うソリューションが必要となり開発されました。
予測:インフルエンザ予測
ARGONetと呼ばれるアプローチで、インフルエンザの予測を行なっている例もあります。ARGONetの前のARGOというアプローチ方法があり、その時は電子カルテ、インフルエンザに関するGoogle検索情報、過去のインフルエンザの発生記録などをデータとして使用していました。
ARGONetでは、ARGOで使用していた電子カルテなどのデータに加え、近隣地域で広がるインフルエンザの時空パターンのデータも使用しています。これにより、予測の誤りを減らしています。精度はGoogle Fru Trendsを凌駕しているそうです。
映像解析:交通量予測
ディープラーニングは、映像を解析して交通量を予測するような用途にも活用されています。例えば、City Visionという製品は熱海市内での交通量調査に活用されており、時間帯別、日別グラフ表示、リアルタイム表示、前日との通行量との比率などを表示する機能を持っています。
この事例は、ディープラーニングの精度向上によって同時に複数人の検出ができるようになったことで、交通量調査などの複雑なタスクも実施できるようになった事例と言えます。
まとめ
ディープラーニングが注目され始めたきっかけから、ディープラーニングの主な4つのモデル、そして最近のトレンドや活用事例について紹介してきました。現在は、いかに良いデータを確保して性能の良いコンピュータを活用できるかという勝負になりつつあります。
ディープラーニングに必要な計算資源を確保したいという場合は、クラウド型のGPUを利用することがです。
クラウド型のGPUがおすすめの理由は大きく分けて3つあります。
- 低コストで迅速な運用ができる
- リモートワークでの運用が容易
- AI技術を身近に利用できる
まず、クラウドGPUはオンプレミスのGPUと比較して低コストでの運用が期待できます。例えば、オンプレミスのGPUを使う場合は、導入の初期費用や環境の移行のコストに時間がかかってしまいます。
クラウド型であれば、必要なときに必要な分だけGPUリソースを確保できるため、初期費用を抑えられると同時に、即日利用ができるなど、スピード感を維持した運用が実現します。低予算での開発とスピードを重視する場合はクラウド型GPUは最適な選択肢と言えます。
また、クラウドGPUは、ネット環境があればどこでもいつでも使えるため、リモートワークでも運用がしやすいです。オフィスでのサーバーが不要であるため、何らかの災害が発生した際にも事業を継続できます。そのため、BCP(Business Continuity Planning:事業継続計画)対策の上でも有効です。
このように、予算や場所の制約が少ないクラウドGPUを活用することで、AIなどの最新テクノロジーを利用しやすい環境になりました。初期投資や環境のアップデートが進められなかった現場でも、クラウドであれば最低限のライセンス料金で利用が可能になります。
そして、クラウドGPUの中でも、シンプルでカスタマイズが自由なM:CPPがおすすめです。M:CPPを活用すれば、「大規模な開発を進めていく前に、一度コストを抑えてテストを行いたい」「オンプレミスのGPUの維持管理コスト負担が気になる」など、GPUの運用に関する課題を一気に解決することが可能です。

大手GPUクラウドと比べても低価格であるため、費用に悩んでいる場合も、M:CPPであれば最適化とオールインワンパッケージの採用により、さらなるコスト削減を期待できるでしょう。
M:CPPについては、こちらのページを参考にしてください。